This is a topic that can cause quite a bit confusion, so here is a short post I can come back to whenever I get confused.
Lets start with the definition of a vector. A vector is… uhmm … I guess you have a rough idea of what a vector is. Otherwise this is stuff for another post.
(The notion vector means here the abstract objects of a vector space. Euclidean vectors (=arrow-like objects) are just one special example. Nevertheless, Euclidean vectors are the example that inspired the idea of abstract vectors. All objects that share some basic properties with Euclidean vectors, without the need of beeing arrow-like objects in Euclidean space, are called vectors.)
One-Forms
A one-form (1-form) is the dual object to a vector: A one-form $ \tilde w()$ eats a vector $V$ and spits out a number
\begin{equation} \tilde w(V) . \end{equation}
The word dual is used, because we can think of a vector $V()$ as an object that eats a one-form $\tilde w$ and spits out a number
\begin{equation} V(\tilde w) \equiv \tilde w(V) . \end{equation}
We will see in a moment why defining such an object is a useful idea.
Two examples:
From matrix algebra: If we decide to call column vectors “vectors”, then row vectors are one-forms. Given a vector $ V=\begin{pmatrix} 2 \\ 4 \end{pmatrix}$, ordinary matrix multiplication (in the correct order) with a one-form $ \tilde w = \begin{pmatrix} 1 & 3 \end{pmatrix}$, results in a single real number:
\begin{equation} \tilde w(V) \equiv \begin{pmatrix} 1 & 3 \end{pmatrix} \begin{pmatrix} 2 \\ 4 \end{pmatrix} = 2+12 = 14
\end{equation}
Another example used in quantum mechanics are bras $\langle\Psi\vert$ and kets $\vert\Phi\rangle$. Kets are used to describe the inital state of a system, bras for the final states. Together they give a single number:
\begin{equation} \langle\Psi\vert \Phi\rangle
\end{equation}
which is the probability amplitude for finding (measuring) the system $\vert \Phi\rangle$ in the final state $\langle\Psi\vert$. Kets, like $\vert \Phi\rangle$ are vectors, and bras, like $\langle\Psi\vert$, are one forms.
Tensors
Tensors are the natural generalization of the ideas described above. Tensors are linear operators on vectors and one-forms. A tensor of type $ \begin{pmatrix}N \\ N’ \end{pmatrix}$, eats $N$ one-forms and $N’$ vectors and spits out a single number.
A $ \begin{pmatrix}2 \\ 0\end{pmatrix}$ tensor is an object $F( \quad , \quad )$ that eats two one-forms, say $\tilde w$ and $\tilde v$ and spits out a number $F( \tilde w , \tilde v )$. A $ \begin{pmatrix}1 \\ 2\end{pmatrix}$ tensor $F( \quad ; \quad , \quad)$ eats 1 one-form $\tilde w$ and 2 vectors, say $V$ and $W$ and spits out a number $F( \tilde w ; V, W)$ .
The term “linear operator” means that tensors obey ( for arbitrary numbers a, b)
\begin{equation} F( a \tilde w + b \tilde v , \tilde z ; V, W) = a F( \tilde w , \tilde z ; V, W) + b F( \tilde v , \tilde z ; V, W)
\end{equation}
and similarly for the other arguments. In general, the order of the arguments makes a difference
\begin{equation} F( \tilde w , \tilde v ) \neq F( \tilde v, \tilde w ),
\end{equation}
just as for a function of real variables, say $f(x,y)=4x+7y$, we have $f(1,3)\neq f(3,1)$.
A special and very important kind of tensors are anti-symmetric tensors. Anti-symmetry means that if we change the order of two arguments, the tensors changes only by a sign:
\begin{equation} F_\mathrm{asym}( \tilde w , \tilde v ) = – F_\mathrm{asym}( \tilde v, \tilde w ).
\end{equation}
Analogous a symmetric tensor does not care about the order of its arguments:
\begin{equation} F_\mathrm{sym}( \tilde w , \tilde v ) = F_\mathrm{asym}( \tilde v, \tilde w ).
\end{equation}
If the tensor has more than two arguments of the same kind, the tensor is said to be totally antisymmetric (symmetric) if it is antisymmetric (symmetric) under the exchange of any of the arguments.
\begin{equation} F_\mathrm{tasym}( \tilde w , \tilde v, \tilde z ) = – F_\mathrm{tasym}( \tilde v, \tilde w ,\tilde z) = F_\mathrm{tasym}( \tilde v,\tilde z, \tilde w ) = – F_\mathrm{tasym}(\tilde z, \tilde v, \tilde w )
\end{equation}
Antisymmetric tensors play a special role in mathematics and therefore they are given a special name: p-forms for antisymmetric $ \begin{pmatrix} 0 \\ p \end{pmatrix}$ tensors , and p-vectors for antisymmetric $ \begin{pmatrix} p \\ 0\end{pmatrix}$ tensors.
P-Forms and P-Vectors
A p-form is simply an (antisymmetric in its arguments) object that eats p vectors and spits out a real number. Analogous a p-vector eats p one-forms and spits out a number (, and is antisymmetric in its arguments). For example a 2-form $\tilde w( , )$, eats two vectors $V$, $W$, spits out a real number $\tilde w(V , W)$, and is antisymmetric in its arguments $\tilde w(V , W) = – \tilde w(W , V)$.
P-forms are important, because they are exactly the objects we need if we want to talk about areas and volumes (and higher dimensional analogues).
If we have a metric (the mathematical object defining length) defining areas and volumes is straight forward. Nevertheless, the notion of area is less restrictive than the notion of metric and we can define area without having to define a metric on the manifold in question.
Lets see how this comes about.
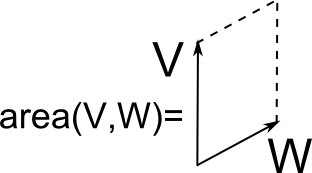
We start by taking a step back and think about what properties a mathematical object, describing area should have. Suppose we have two (possibly infinitesimal) vectors, forming a two-dimensional parallelogram and we need the mathematical object that tells us the area of this parallelogram:
\begin{equation} \mathrm{area}(V,W) = \text{ area of the parallelogram formed by V and W}.
\end{equation}
An obious property is that the number $\mathrm{area}(V,W)$ ought to double if we double the length of one vector:
\begin{equation} \mathrm{area}(2V,W) = 2 \times \text{ area of the parallelogram formed by V and W}
\end{equation}
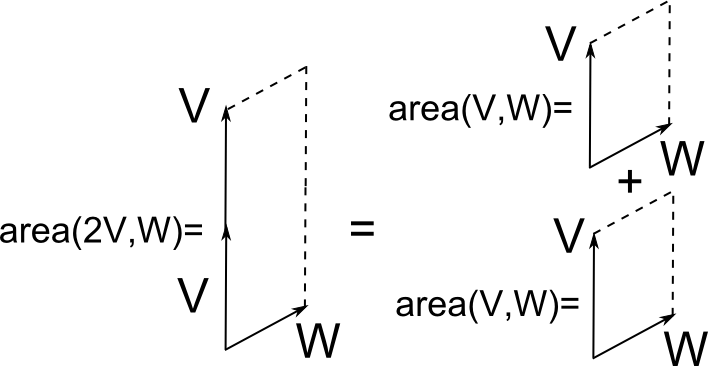
In addition, the area object should be additive under the addition of vectors
\begin{equation} \mathrm{area}(V,W+Z) = \mathrm{area}(V,W) + \mathrm{area}(V,Z)
\end{equation}
A pictorial proof can be seen in the following figure:
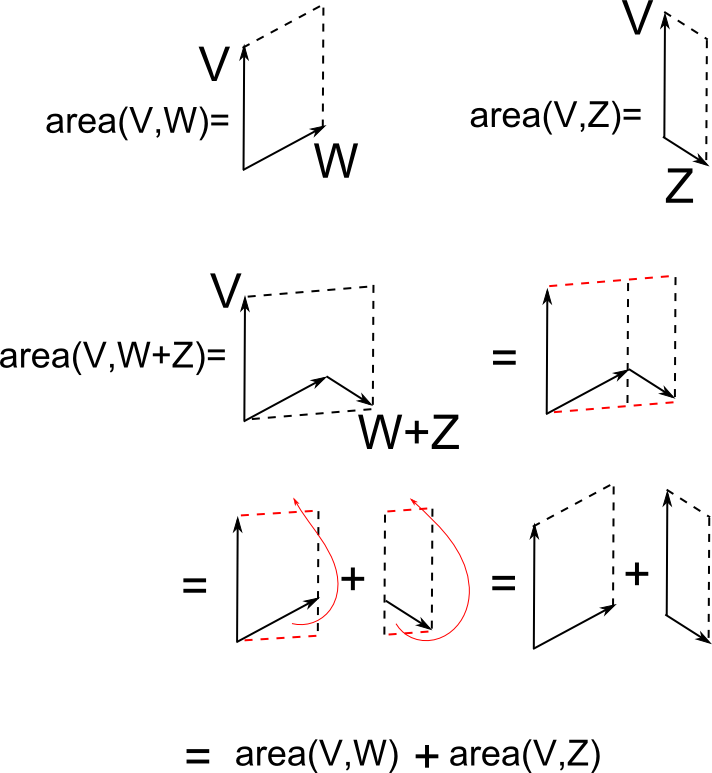
Together these properties are what we called linearity above, and we see that this fits perfectly with the defintion of a $ \begin{pmatrix} 0 \\ 2 \end{pmatrix}$ tensor.
Another 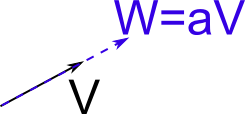 important propery is that $\mathrm{area}(V,W) $ must vanish if $V$ and $W$ are parallel, i.e. if $W=aV$ for some number $a$, we have
important propery is that $\mathrm{area}(V,W) $ must vanish if $V$ and $W$ are parallel, i.e. if $W=aV$ for some number $a$, we have
\begin{equation} \mathrm{area}(V,W) =\mathrm{area}(V,aV)
\stackrel{!}{=} 0.
\end{equation}
.Because we have $\mathrm{area}(V,aV)=a \times \mathrm{area}(V,V) \stackrel{!}{=} 0$, we start with $\mathrm{area}(V,V) \stackrel{!}{=} 0$ in the next step to see that $\mathrm{area}(V,W)$ must be an antisymmetric $ \begin{pmatrix} 0 \\ 2 \end{pmatrix}$ tensor.
The proof is simple: From
\begin{equation} \mathrm{area}(V,V) = 0,
\end{equation}
if we write $V= U+W$, it follows
\begin{equation} \mathrm{area}(U+W,U+W) = 0.
\end{equation}
Using the linearity yields
\begin{equation} \mathrm{area}(U,U) + \mathrm{area}(U,W) + \mathrm{area}(W,U) + \mathrm{area}(W,W) = 0.
\end{equation}
Using now $\mathrm{area}(V,V) = 0$ for $W$ and $U$, i.e., $\mathrm{area}(W,W) = 0$, $\mathrm{area}(U,U) = 0$, yields
\begin{equation} \underbrace{\mathrm{area}(U,U)}_{=0} + \mathrm{area}(U,W) + \mathrm{area}(W,U) + \underbrace{\mathrm{area}(W,W)}_{=0} = \mathrm{area}(U,W) + \mathrm{area}(W,U) = 0 .
\end{equation}
\begin{equation} \rightarrow \mathrm{area}(U,W) = – \mathrm{area}(W,U). \end{equation}
We conclude that demanding $\mathrm{area}(V,aV) \stackrel{!}{=} 0$, leads us directly to the property $\mathrm{area}(U,W) = – \mathrm{area}(W,U) $ of the area object. This is what we call antisymmetry.
Therefore, the appropriate mathematical object to describe area is an antisymmetric $ \begin{pmatrix} 0 \\ 2 \end{pmatrix}$ tensor, which we call a 2-form.